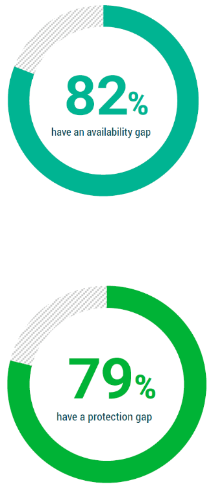
Disaster Recovery to zagadnienie, które w ostatnim czasie zyskuje na popularności – firmy coraz częściej dostrzegają potrzebę odtwarzania awaryjnego po „zdarzeniu niszczącym” lub po incydencie bezpieczeństwa. Potwierdzają to również dane – według raportu Veeam ,,Trendy w ochronie danych 2021”, popularność rozwiązań Disaster Recovery wzrosła w ciągu ostatnich dwóch lat o niemal 1/5 (19%). Nic w tym dziwnego, zważywszy na fakt, iż skuteczne wdrożenie rozwiązań z obszaru DR to dla dużych organizacji oraz MŚP główne zabezpieczenie przed zaburzeniem ciągłości działania, a co za tym idzie, ochrona przed szeregiem konsekwencji technicznych, finansowych i wizerunkowych.
Obszar Disaster Recovery jest dość pojemny i zazwyczaj błędnie interpretowany, zwłaszcza w aspekcie definicyjnym. Dlatego postanowiliśmy nieco uporządkować to zagadnienie, osadzając je odpowiednio wśród innych rozwiązań i strategii cyberodporności. W tym celu zapraszamy Was do rozmowy z Tomaszem Magdą – Product Managerem Flowberg IT, który od niemal dekady specjalizuje się w rozwiązaniach z obszaru ciągłości działania, odtwarzania awaryjnego i wysokiej dostępności.
Na początek jednak polecamy krótką ściągawkę, która pozwoli Wam odnaleźć się w gąszczu akronimów, anglojęzycznych nazw i definicji.
Ciągłość działania – dotyczy zwykle organizacji i oznacza zdolność do utrzymania krytycznych operacji (procesów) nawet, gdy wystąpią istotne przeszkody. Dotyczy to wszelkich sfer funkcjonowania organizacji oraz skutków wpływu czynników mikro- i makroekonomicznych.
Business Continuity Plan – BCP (Plan Ciągłości Działania) – dokument określający strategię działania w celu zabezpieczenia ciągłości działania organizacji. Opisuje kroki, które należy podjąć przed, w trakcie lub w odpowiedzi na nieoczekiwane sytuacje, które zagrażają działalności firmy. Do zdarzeń zakłócających ciągłość działania możemy zaliczyć: klęski żywiołowe, zdarzenia niszczące, w tym pożar czy zalanie, utratę danych czy zatrzymanie lub zaszyfrowanie przez Ransomware systemów informatycznych organizacji. Zadaniem BCP jest identyfikacja ryzyk oraz spisanie procedur mających na celu zagrożeniom zewnętrznym, minimalizowanie ich potencjalnych skutków (Business Impact Analysys) oraz redukowanie potencjalnych przestojów wynikających z nieprzewidzianych zdarzeń, które bezpośrednio dotykają organizację.
Disaster Recovery (Odtwarzanie awaryjne) – szereg zaplanowanych i opisanych działań mających na celu przywrócenie dostępności i funkcjonalności infrastruktury IT po zdarzeniach niszczących zasoby lub dane. Instrukcje i procedury dotyczące odzyskiwania po awarii są zwykle zawarte w Planie Odtwarzania Awaryjnego obszaru IT (IT Disaster Recovery Plan), który jest elementem Planu Ciągłości Działania.
Disaster Recovery as a Service (DRaaS) – outsourcing usług obszaru odtwarzania awaryjnego, którego podstawowe elementy to aplikacje, łączność sieciowa, pamięć masowa oraz moc obliczeniowa po stronie usługodawcy. Usługa umożliwia replikowanie krytycznych systemów i danych z ośrodka podstawowego (czyli z infrastruktury klienta) do centrum danych usługodawcy. Celem takiego działania jest zapewnienie zdolności do szybkiego uruchomienia całego lub części środowiska w infrastrukturze dostawcy usługi, w razie gdy wystąpi zdarzenie niszczące dane lub systemy w ośrodku klienta.
Backup – procedura regularnego tworzenia kopii zapasowych plików i obrazów całych maszyn, która pozwala odzyskać dane i przywrócić działanie systemów oraz aplikacji po awarii lub incydencie naruszającym spójność danych. Opracowana i wdrożona polityka backupu w organizacji jest częścią Planu Odtwarzania Awaryjnego Obszaru IT.
Wszystko jasne? No to zapraszamy do wywiadu.
1. Wdrożenie i utrzymanie rozwiązań z zakresu Disaster Recovery to często dla firm być albo nie być. Skoro tak, czy w Polsce ta praktyka jest standardem? I co za tym idzie – ilu szacunkowo mamy specjalistów lub firm specjalizujących się w DR w Polsce?
W organizacjach procesy powinny mieć swojego właściciela, żeby działały prawidłowo, dlatego też szczególnie średnie i duże firmy rzeczywiście powinny zapewnić w swoich szeregach osoby, które opracowują, wdrażają oraz testują plany odtwarzania awaryjnego, będące częścią Planów Ciągłości Działania (Business Continuity Plan). Dość częstą praktyką jest sięganie po outsourcing w zakresie tworzenia planów – wówczas samym utrzymaniem i aktualizacją może zająć się osoba z mniejszym doświadczeniem.
W polskich firmach zainteresowanie obszarem Odtwarzania Awaryjnego jest małe, co niejako implikuje niewielką podaż osób, które się tym zajmują. Co ciekawe, na świecie funkcjonują 4 instytucje certyfikujące osoby zajmujące się Disaster Recovery (DR):
- DRI International (USA),
- Certified Information Security (USA),
- Mile2 (USA),
- EC-Council (USA).
Każda z nich ma opracowaną ścieżkę certyfikacji dla specjalistów DR i trzeba podkreślić, że jest to droga dla ludzi bardzo zdeterminowanych 😊. Na przykład, aby zdobyć Certified Business Continuity Professional (CBCP) wydawany przez DRI International, kandydaci muszą wykazać się dziesięcioletnim doświadczeniem w obszarze Business Continuity Management. Mało tego, trzeba napisać 5 esejów, z których 2 muszą dotyczyć: analizy wpływu na biznes (BIA), tworzenia strategii ciągłości działania, opracowywania i wdrażania planów ciągłości działania lub utrzymywania oraz testowania planów ciągłości działania. Koszt szkolenia i egzaminu wynosi 2900 USD. Recertyfikacja jest wymagana corocznie i jeszcze trzeba wnosić opłatę roczną za utrzymanie certyfikatu. A to jeszcze nie koniec – trzeba także zdobywać punkty aktywności edukacyjnej (CEAP), aby zachować certyfikację – 80 punktów na 2 lata.
Jak więc widać, zdobycie i utrzymanie certyfikacji potwierdzającej kompetencje w zakresie Disaster Recovery wymaga wielu zabiegów. Nadmienię jeszcze, że nie słyszałem, by ktoś w Polsce zdobył ten certyfikat.
2. Czy z cyberzagrożeniami jest trochę tak jak w serialu „Haker”, że każdy system można obejść, w efekcie niszcząc jego dane? Co wtedy? Czy zawsze można odzyskać dane po ataku?
Nie oglądałem serialu „Haker”, ale niestety tak – nie ma systemu, do którego nie można się włamać. Zawsze jest jakiś słaby punkt. W dodatku sztuczka z odzyskiwaniem danych po incydencie udaje się zwykle tylko w filmach. Trzeba też pamiętać, że atak może dotknąć każdego, gdyż wraz z popularyzacją modelu Ransomware as a Service, liczba automatycznych ataków na dane wzrasta wykładniczo. Stworzenie przez cyberprzestępców kanału pośredniego, opartego o oprogramowanie do szyfrowania danych i wymuszania okupów, naprawdę daje w kość przedsiębiorcom, także i w Polsce.
Dlatego tak ważne jest odpowiednie zabezpieczanie danych, a więc budowanie odpornej na ataki architektury systemów backupu. Samo wdrożenie reguły 3-2-1, której elementem jest przechowywanie kopii zapasowych w innej lokalizacji (off-site backup / backup poza siedzibą), potrafi uratować organizację w obliczu udanego ataku Ransomware, czy też innego incydentu bezpieczeństwa wycelowanego w pamięć masową. Kopia zapasowa przechowywana poza zaatakowanym środowiskiem staje się ostatecznym zabezpieczeniem kluczowym dla odzyskania danych i odtworzenia systemów.
3. Z jakimi wyzwaniami z zakresu ochrony danych najczęściej mierzycie się w Waszej pracy?
Przypadki są najróżniejsze, ale łączy je jedno – nie doszłoby do nich, gdyby nie określona liczba zaniedbań i informatyczna brawura. Niestety, zwykle impulsem do wdrażania zmian w zakresie ochrony danych jest incydent bezpieczeństwa. Wtedy dopiero wychodzą na jaw różne fakty i potwierdza się uniwersalna zasada – ufaj, ale sprawdzaj. Pozytywne jest to, że w sytuacji zagrożenia ciągłości działania organizacji, wszyscy grają do jednej bramki, a dzięki temu można na przykład w tydzień wdrożyć coś, co do tej pory odkładano latami. Zwykle wtedy – wspólnie z zespołem klienta – układamy wiele obszarów na nowo, w każdym razie inaczej, zgodnie z najlepszymi praktykami w zakresie cyberodporności.
Na liście klasycznych błędów, które bardzo często spotykamy przy okazji wdrożeń, czy interwencji, umieściłbym:
- Przechowywanie kopii zapasowych na tej samej pamięci masowej, na której znajdują się dane produkcyjne, a do tego traktowanie zrzutów migawkowych jako backupu.
- Przyjęcie jednej ogólnej zasady wykonywania kopii zapasowych dla wszystkich systemów, bez rozróżnienia, czy mamy do czynienia z bazą danych, czy z repozytorium plików albo aplikacją. Efektem jest np. brak spójności transakcyjnej baz danych po odtworzeniu.
- Rozproszenie zadań backupu między różne systemy, wynikające najczęściej z pozornej oszczędności na wdrożeniu centralnego systemu backupu.
- Brak testów odtwarzania z kopii zapasowej, co nierzadko zamienia się w katastrofę, gdy po incydencie okazuje się, że nie można odtworzyć danych z kopii.
- Brak osoby odpowiedzialnej za proces backupu i odtwarzania w firmie.
4. Od czego powinna zacząć organizacja, która chce wdrożyć rozwiązania Disaster Recovery?
Osobiście rekomenduję działanie, jakim jest spisanie Planu Odtwarzania Awaryjnego Obszaru IT. I nie chodzi tu o tworzenie kilkudziesięciostronicowego tomiszcza, lecz o napisaną prostym językiem, kilkustronicową instrukcję opisującą, co i w jaki sposób mamy robić w określonej sytuacji. Chodzi o to, by wiedzieć co robić, gdy zmaterializuje się określone ryzyko – wtedy najważniejsze jest szybkie i zdecydowane działanie, czyli procedowanie zgodnie z wcześniej zaplanowanym schematem. W sytuacji awaryjnej nie ma miejsca na to, żeby dopiero zabierać się za obmyślanie rozwiązania. Ważne jest też, by ten dokument był stale dostępny dla zespołu odpowiedzialnego za Disaster Recovery w firmie. Należy też, rzecz jasna, aktualizować procedury w zgodzie ze zmianami wprowadzanymi w środowiskach IT. Tworząc plan, dokonujemy inwentaryzacji i hierarchizacji zasobów, co w następnych krokach pomoże w doborze właściwego rozwiązania technicznego.
5. Czy Disaster Recovery polega wyłącznie na odtwarzaniu awaryjnym danych?
Disaster Recovery nie ogranicza się do odtworzenia danych. To raczej zespół działań, procesów i procedur, mających na celu zarówno zabezpieczenie przed awarią, jak i przywrócenie działania usług IT, gdy awaria wystąpi. Chodzi o to, by jak najszybciej przywrócić zdolność organizacji do prowadzenia działalności operacyjnej. Ważne jest przy tym, by rozróżnić odtwarzanie z backupu od przełączenia awaryjnego na środowisko zapasowe. Wyciąganie danych z backupu to zwykle czasochłonny proces związany z kopiowaniem danych z repozytorium backupu na docelową pamięć masową i niestety nie zawsze kończy się on sukcesem.
Weźmy następujący scenariusz dla lepszego zwizualizowania istoty Disaster Recovery. W średniej firmie wydawniczej awarii uległa macierz dyskowa, na której pracują systemy produkcyjne, albo – co zdarza się o wiele częściej – macierz trzeba odłączyć i zabezpieczyć jako dowód w postępowaniu po cyberincydencie. Co w takiej sytuacji da nam backup danych? No właśnie, mamy spory problem. Dlatego podczas planowania odtwarzania awaryjnego od razu trzeba zdecydować, na jakich zasobach realizowane będą fazy failover czy partial-failover – czyli innymi słowy, gdzie będzie odbywać się przetwarzanie danych w sytuacji przełączenia awaryjnego.
6. Jak w praktyce realizowane jest Disaster Recovery w organizacji? Jaka technologia sprawdza się najlepiej i dlaczego?
W uproszczeniu, odtwarzanie awaryjne opieramy na backupie i replikacji. Zasadniczym celem backupu jest długoterminowa ochrona danych, natomiast celem replikacji jest zapewnienie dostępności systemów, np. w innej lokalizacji. Planując Odtwarzanie Awaryjne należy uwzględnić zarówno backup jak i replikację. Tylko takie podejście do DR pozwoli dostosować scenariusze odtworzeniowe do rodzaju i dotkliwości incydentu bezpieczeństwa, czy też stopnia wpływu czynnika niszczącego.
W praktyce DR to sekwencyjna replikacja asynchroniczna – a rzadziej synchroniczna – do drugiego ośrodka przetwarzania lub do chmury. Replikujemy zwykle wirtualne maszyny utrzymujące procesy krytyczne w organizacji. W przypadku awarii ośrodka podstawowego, z takich replik składowanych w ośrodku zapasowym można uruchomić środowisko IT i przełączyć pracę właśnie na ten ośrodek (failover). Po tym, gdy uzyskamy zdolność do ponownego uruchomienia ośrodka podstawowego, następuje faza failback, w której maszyny ośrodka podstawowego synchronizowane są o zmiany, które zaszły w ośrodku zapasowym. Pomyślne zakończenie fazy failback pozwala na ponowne przełączenie przetwarzania na ośrodek podstawowy.

Rysunek 1 – Fazy DRC & DRaaS | replikacja | failover | failback
Jeżeli chodzi o technologię, to trzeba ją bezwzględnie dopasować do stosu technologicznego, który już posiadamy. Nadto, należy uwzględnić istniejące procedury, plany ciągłości działania i oczekiwania biznesowe w zakresie akceptowalnej utraty danych, jak i czasu przywracania – parametry RPO (Recovery Point Objective) i RTO (Recovery Time Objective).

Rysunek 2 – Disaster Recovery – RPO & RTO
My realizujemy wdrożenia Disaster Recovery albo jako projekty DRC, albo jako usługę poziomu aplikacji – DRaaS. W drugim przypadku preferujemy rozwiązanie firmy Veeam Software, której jesteśmy partnerem w programie Veeam Cloud Service Provider (poziom Gold).
7. Coraz większą popularnością wśród polskich firm cieszy się od jakiegoś czasu DRaaS, czyli Disaster Recovery w formie usługi. Wyjaśnij proszę, na czym ona polega i jaka jest różnica pomiędzy DRC, a DraaS?
Generalnie model „as a Service” zdobywa rynek. Nie zawsze jednak jest on możliwy do zastosowania. Na przykład, jeżeli chodzi o Disaster Recovery, czym bardziej niszowa technologia i wyśrubowane parametry RTO/RPO, tym bardziej nieuchronne jest użycie klasycznego podejścia, czyli Disaster Recovery Center. Jest to z resztą najstarszy i najdroższy sposób realizacji DR. Polega na zdublowaniu części infrastruktury serwerowej oraz sieciowej i umieszczeniu jej w innej lokalizacji, np. w centrum danych dostawcy (kolokacja). Taka nadmiarowość oparta na dwóch centrach danych umożliwia replikację synchroniczną lub asynchroniczną wszelkich krytycznych maszyn wirtualnych i ustawień wraz z danymi, a więc de facto pozwala na utrzymywanie klona środowiska podstawowego. W oparciu o tak zaprojektowane środowisko zapasowe, można dokonać przełączenia awaryjnego (failover), a po określonym czasie wykonać failback i przełączyć się ponownie na przetwarzanie w oparciu o ośrodek podstawowy.
W przypadku stosowania popularnych technologii komercyjnych, głównie w zakresie wirtualizacji (vSphere, Hyper-V), wachlarz możliwości realizacji DR jest o wiele szerszy. Przede wszystkim, możliwe jest skorzystanie z gotowych usług budowanych przez centra danych, hyperscalerów czy dostawców usług. Wówczas unikamy inwestycji, a usługę DR odbieramy w modelu abonamentowym (Opex). Nadal możliwe jest uruchamianie awaryjne z replik, z tą różnicą, że zamiast na własnych serwerach ośrodka zapasowego, odtwarzanie następuje w chmurze dostawcy (IaaS). Na tym właśnie polega Disaster Recovery as a Service.
Usługodawcy zwykle proponują pełny outsourcing i oferują wsparcie techniczne oraz administracyjne doświadczonego w tym obszarze inżyniera IT, bo jak już wspomniałem, wiedza wdrożeniowa z tego obszaru nie jest w Polsce zbyt powszechna.
Rozmawiała: Natalia Dutkiewicz
Artykuł został napisany przez człowieka, a nie algorytm sztucznej inteligencji.