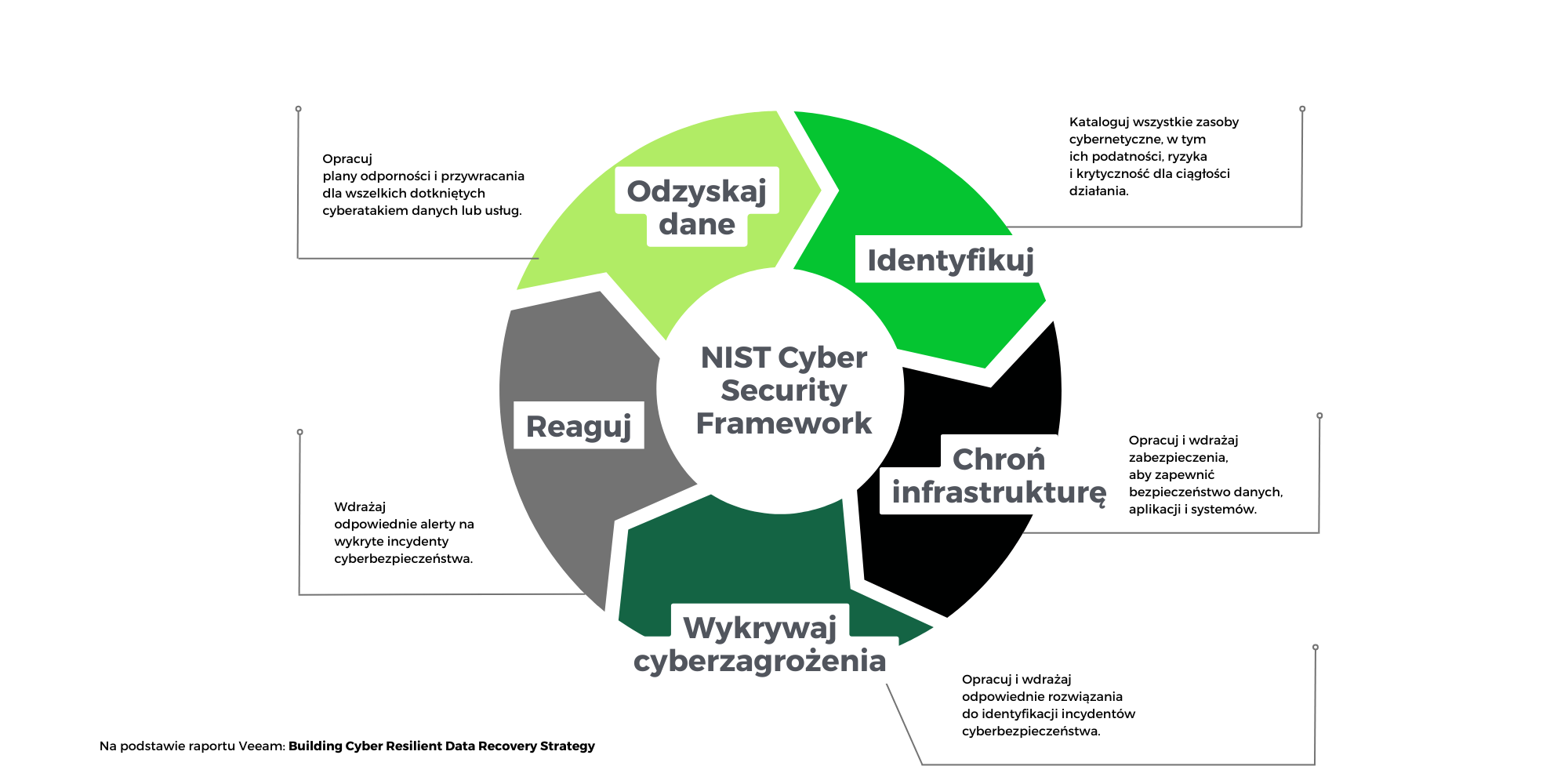
Wprowadzenie
Centra danych stanowią kluczowy element infrastruktury, umożliwiając przetwarzanie, przechowywanie i zarządzanie ogromnymi ilościami danych. Polska, z racji swojego strategicznego położenia, atrakcyjnych kosztów energetycznych oraz rosnącej liczby wykwalifikowanych specjalistów IT, ma potencjał, aby stać się europejskim hubem danych. Niniejszy artykuł analizuje kluczowe czynniki wpływające na rozwój rynku Data Center w Polsce, przedstawiając tezę, że Polska ma możliwość przekształcenia się w centrum danych dla całej Europy. Argumenty przedstawione w artykule opierają się na najnowszych danych rynkowych, trendach technologicznych oraz inwestycjach w infrastrukturę. Dodatkowo przeprowadziliśmy krótki wywiad z Robertem Kucnerem Dyrektorem ds. sprzedaży usług DC/Cloud, w firmie FLowberg IT, na temat wrocławskiego Centrum Danych.
Kluczowe Czynniki Napędzające Rozwój Rynku
Postępy Technologiczne
Postęp technologiczny jest jednym z najważniejszych czynników napędzających rozwój rynku centrów danych w Polsce. Infrastruktura światłowodowa i technologie 5G odgrywają kluczową rolę w tym procesie. Według raportu Mordor Intelligence, penetracja technologii światłowodowej (FTTP) w Polsce wzrosła z 44,6% w 2020 roku do około 51,9% w 2021 roku. Przykładem innowacji technologicznych, które wspierają rozwój rynku, jest wprowadzenie przez Cisco Systems Inc. nowych przełączników, które zwiększają szybkość i gęstość portów.
Rozwój technologii 5G, która zapewnia niskie opóźnienia i wysoką przepustowość, jest kolejnym kluczowym czynnikiem. Polska już teraz inwestuje w rozwój sieci 5G, co przyczyni się do wzrostu zapotrzebowania na centra danych, które będą mogły obsługiwać większe ilości danych w krótszym czasie.
Rosnące Zapotrzebowanie Konsumentów
Wzrost zapotrzebowania na usługi chmurowe, Internet Rzeczy (IoT), Big Data oraz technologie immersyjne, takie jak VR i AR, znacząco wpływa na rozwój centrów danych w Polsce. Pandemia COVID-19 przyspieszyła cyfryzację, zwiększając zapotrzebowanie na lokalne serwery i niskie opóźnienia danych. Wzrost zapotrzebowania konsumentów na szybkie i niezawodne usługi internetowe, wspierane przez rozwój infrastruktury światłowodowej, przyczynia się do ekspansji rynku.
Inwestycje w Infrastrukturę
Znaczące inwestycje w rozwój infrastruktury centrów danych w Polsce są kluczowe dla ich wzrostu. Inwestycje te są wspierane przez fundusze takie jak Recovery and Resilience Facility (RRF) oraz European Regional Development Fund (ERDF), które mają na celu zwiększenie inkluzji szerokopasmowej w Polsce.
Dobrym przykładem jest certyfikowane Data Center obsługiwane przez firmę Flowberg IT z siedzibą we Wrocławiu. Ten nowoczesny Obiekt oferuje zaawansowane technologicznie rozwiązania, które zapewniają wysoką dostępność, bezpieczeństwo i skalowalność usług.
Aby lepiej zrozumieć, jak Flowberg IT realizuje swoje cele i plany, przeprowadziliśmy wywiad z Robertem Kucnerem, Dyrektorem ds. Sprzedaży Usług DC/Cloud, w Flowberg IT.
Rozmowa dotyczyła informacji na temat unikalnych atutów wspomnianego Data Center we Wrocławiu, oferty usług, znaczenia lokalizacji oraz przyszłych planów rozwoju firmy.
Jakie są główne atuty Data Center Flowberg IT we Wrocławiu, które wyróżniają Was na tle konkurencji?
Robert Kucner: Data Center Flowberg IT we Wrocławiu wyróżnia się przede wszystkim nowoczesną infrastrukturą technologiczną. Posiadamy zaawansowane systemy, które zapewniają nieprzerwaną pracę nawet w przypadku awarii. Nasze centrum danych jest również wyposażone w systemy redundancji sieciowej, co minimalizuje ryzyko przestojów. Dodatkowo, spełniamy rygorystyczne normy bezpieczeństwa, w tym standardy ISO oraz certyfikacje dotyczące ochrony danych osobowych. Wszystko to sprawia, że możemy zapewnić naszym klientom najwyższy poziom usług i bezpieczeństwa danych.
Jakie usługi oferuje Flowberg IT i jakie są ich główne zalety?
Robert Kucner: Oferujemy szeroki zakres usług, w tym kolokację, usługi chmurowe, zarządzane usługi IT oraz rozwiązania z zakresu cyberbezpieczeństwa i connectivity. Nasze usługi chmurowe są skalowalne i elastyczne, co pozwala klientom dostosować je do swoich zmieniających się potrzeb. Dzięki usłudze kolokacji firmy mogą umieścić swoje serwery w naszym centrum danych, co zapewnia im dostęp do zaawansowanej infrastruktury bez konieczności ponoszenia dużych kosztów inwestycyjnych związanych z zapewnieniem redundantnego zasilania, chłodzenia czy też bezpieczeństwa fizycznego. Nasze usługi zarządzane pozwalają klientom skupić się na swoim głównym biznesie, podczas gdy my zajmujemy się zarządzaniem ich infrastrukturą IT.
Jakie znaczenie ma lokalizacja centrum danych we Wrocławiu dla Waszych klientów?
Robert Kucner: Wrocław jest strategicznie położony, co umożliwia szybki dostęp do kluczowych rynków w Europie Środkowo-Wschodniej. Miasto posiada dobrze rozwiniętą infrastrukturę transportową i telekomunikacyjną, co dodatkowo podnosi jego atrakcyjność. Dla naszych klientów oznacza to nie tylko szybki i niezawodny dostęp do ich danych, ale także korzyści z niskich kosztów operacyjnych w porównaniu do innych lokalizacji w Europie oraz dużą dostępność.
Jakie są najważniejsze inwestycje Flowberg IT w najnowsze technologie i rozwój kadry?
Robert Kucner: Inwestujemy znaczne środki w najnowsze technologie, aby zapewnić naszym klientom najwyższą jakość usług. Regularnie modernizujemy nasze systemy chłodzenia, zasilania i zabezpieczeń, aby spełniały najwyższe standardy. Staramy się być również na bieżąco z najnowszymi trendami i technologiami w branży IT.
Jakie są plany rozwoju Flowberg IT na najbliższe lata?
Robert Kucner: Planujemy dalszą ekspansję naszych usług chmurowych oraz rozwój nowych rozwiązań z zakresu cyberbezpieczeństwa. Chcemy również zwiększyć naszą obecność na rynkach międzynarodowych, oferując nasze usługi klientom spoza Polski. Naszym celem jest stać się liderem w dostarczaniu nowoczesnych i bezpiecznych rozwiązań IT, które pomagają naszym klientom osiągać ich cele biznesowe.
W jaki sposób Flowberg IT zapewnia bezpieczeństwo danych przechowywanych w Waszym centrum danych?
Robert Kucner: Bezpieczeństwo danych jest dla nas priorytetem. Nasze centrum danych jest zabezpieczone na wielu poziomach – fizycznym, technicznym i proceduralnym. Posiadamy zaawansowane systemy kontroli dostępu, monitoring 24/7 oraz zabezpieczenia fizyczne. Dodatkowo, nasze systemy IT są chronione przez nowoczesne rozwiązania z zakresu cyberbezpieczeństwa, które są regularnie aktualizowane przez zespół SOC (Security Operation Center) aby zapewnić najwyższy poziom ochrony przed zagrożeniami.
Jakie korzyści przynosi firmom korzystanie z usług kolokacji w Flowberg IT?
Robert Kucner: Korzystanie z usług kolokacji pozwala firmom, które wymagają bezpiecznego, niezawodnego i efektywnego kosztowo środowiska dla swoich serwerów i sprzętu IT. na umieszczenie ich w naszym centrum danych. Skorzystanie z usługi pozwala na redukcję kosztów związanych z budową, utrzymaniem i modernizacją własnej infrastruktury IT. Dodatkowo, firmy mogą skupić się na swoim głównym biznesie, ponieważ to my zajmujemy się zarządzaniem infrastrukturą IT. Nasze usługi kolokacji zapewniają także skalowalność, co pozwala firmom na łatwe dostosowanie zasobów IT do zmieniających się potrzeb.
Jakie są główne cechy serwerów dedykowanych oferowanych przez Flowberg IT?
Robert Kucner: Serwery dedykowane oferowane przez Flowberg IT to rozwiązania, które zapewniają pełną kontrolę nad zasobami serwera, najwyższy poziom bezpieczeństwa oraz wydajność. Oferujemy zarówno serwery dedykowane niezarządzane, które dają klientom pełną swobodę w zarządzaniu infrastrukturą, jak i serwery dedykowane zarządzane, gdzie zajmujemy się procesem zarządzania, w tym kopii zapasowych, bezpieczeństwa i aktualizacji oprogramowania. To idealne rozwiązanie dla firm, które potrzebują niezawodnych i wydajnych systemów IT.
Jakie są główne zalety korzystania z serwerów VPS w porównaniu do tradycyjnych rozwiązań hostingowych?
Robert Kucner: Serwery VPS oferują liczne korzyści w porównaniu do tradycyjnych rozwiązań hostingowych. Przede wszystkim zapewniają większą niezależność i elastyczność dzięki izolacji zasobów, co oznacza, że działanie innych VPS na tym samym serwerze nie wpływa na wydajność Twojej maszyny. VPS daje pełną kontrolę nad konfiguracją i zarządzaniem serwerem, możliwość skalowania zasobów według potrzeb, lepszą wydajność, oraz wyższy poziom bezpieczeństwa. Jest to idealne rozwiązanie dla stron internetowych, aplikacji, sklepów online i projektów developerskich.
Jakie są możliwości rozbudowy i skalowalności infrastruktury w Waszym centrum danych?
Robert Kucner: Nasze centrum danych zostało zaprojektowane z myślą o skalowalności i elastyczności. Posiadamy łączną powierzchnię 5000 m², z czego 1300 m² to komory kolokacyjne. Każda z komór jest przygotowana w taki sposób, aby dostosować rozwiązania do indywidualnych potrzeb klientów. Dzięki temu możemy łatwo rozbudować infrastrukturę w miarę wzrostu wymagań naszych klientów.
Jakie są dostępne zasoby energetyczne w Flowberg IT?
Robert Kucner: Nasze centrum danych posiada stałe zasilanie dzięki dwóm niezależnym liniom średniego napięcia o łącznej mocy 10 MW. Dodatkowo, posiadamy agregat prądotwórczy o mocy 2,5 MW oraz system UPS, który gwarantuje podtrzymanie zasilania serwerowni przy pełnym obciążeniu. Dzięki temu jesteśmy w stanie zapewnić nieprzerwaną pracę nawet w przypadku awarii zewnętrznych źródeł zasilania.
Jakie są główne wyzwania, z którymi mierzy się Flowberg IT, i jak sobie z nimi radzicie?
Robert Kucner: Jednym z głównych wyzwań jest ciągłe zapewnienie bezpieczeństwa danych w obliczu szybko zmieniających się zagrożeń cybernetycznych. Aby temu sprostać, regularnie aktualizujemy nasze systemy zabezpieczeń i szkolimy nasz zespół w zakresie najnowszych technologii i metod obrony. Kolejnym wyzwaniem jest rosnąca konkurencja na rynku centrów danych. Staramy się wyróżniać, oferując najwyższą jakość usług, elastyczność i indywidualne podejście do każdego klienta.
Polska jako Europejski Hub Danych: Perspektywy i Wyzwania
Perspektywy
- Strategiczne Położenie i Koszty Energetyczne
Polska ma strategiczne położenie w Europie, co czyni ją idealnym miejscem dla centrów danych obsługujących cały kontynent. Dodatkowo, Polska ma jedne z najniższych kosztów energii dla przedsiębiorstw w Unii Europejskiej, co jest istotnym czynnikiem przyciągającym inwestycje. Planowany gazociąg do Norwegii, który poprawi bezpieczeństwo energetyczne kraju, również przyczynia się do atrakcyjności Polski jako hubu danych.
- Koszty Budowy i Dostępność Zasobów Ludzkich
Relatywnie niskie koszty budowy i niskie ceny gruntów, w połączeniu z dostępem do wykwalifikowanej siły roboczej, szczególnie w obszarze IT, są dodatkowymi atutami Polski. Wzrost liczby specjalistów IT oraz inwestycje w edukację technologiczną wspierają rozwój sektora centrów danych.
- Polityka i Regulacje
Polska jest dobrze przygotowana do przyjęcia roli hubu danych dzięki korzystnym regulacjom prawnym, takim jak usunięcie przeszkód dla swobodnego przepływu danych nieosobowych między państwami członkowskimi UE. Dodatkowo, przepisy dotyczące ochrony danych, w tym RODO, zwiększają zapotrzebowanie na lokalne centra danych.
Wyzwania
- Złożoność Regulacyjna i Konkurencja
Jednym z głównych wyzwań jest złożoność regulacyjna oraz intensywna konkurencja na rynku. Firmy muszą dostosowywać się do różnorodnych przepisów krajowych i unijnych, co może być czasochłonne i kosztowne. Konkurencja ze strony innych krajów europejskich, które również inwestują w rozwój centrów danych, stanowi dodatkowe wyzwanie.
- Brak Wykwalifikowanej Kadry
Mimo że Polska posiada dużą liczbę wykwalifikowanych specjalistów IT, nadal istnieje niedobór wysoko wykwalifikowanej kadry w niektórych obszarach technologii. To może ograniczać zdolność do szybkiego skalowania operacji i wdrażania nowych technologii.
- Zrównoważony rozwój
Rosnące zapotrzebowanie na centra danych wiąże się z koniecznością zapewnienia zrównoważonego rozwoju. Wysokie zużycie energii stawia przed firmami wyzwania związane z ekologicznym zarządzaniem i redukcją śladu węglowego. Firmy muszą inwestować w rozwiązania energooszczędne i odnawialne źródła energii, aby sprostać wymaganiom ekologicznym i regulacyjnym.
Przyszłość Rynku Rozwiązań Sieciowych Centrów Danych w Polsce
Innowacje i Technologie Przyszłości
W przyszłości kluczowe znaczenie będą miały innowacje i nowe technologie, takie jak sztuczna inteligencja, Internet Rzeczy, Big Data oraz technologie immersyjne. Rozwój tych technologii zwiększy zapotrzebowanie na centra danych zdolne do obsługi ogromnych ilości danych i zapewnienia niskich opóźnień.
Sztuczna inteligencja (AI) i uczenie maszynowe (ML) stają się coraz bardziej powszechne w różnych sektorach, co zwiększa zapotrzebowanie na centra danych zdolne do obsługi zaawansowanych algorytmów i dużych zbiorów danych. AI może również być wykorzystywana do optymalizacji zarządzania centrami danych, poprawy efektywności energetycznej i zwiększenia bezpieczeństwa.
Wzrost Adopcji Usług Chmurowych
Przewiduje się, że adopcja usług chmurowych będzie nadal rosnąć, napędzana przez małe i średnie przedsiębiorstwa (MŚP) oraz duże korporacje. Usługi chmurowe oferują elastyczność, skalowalność i oszczędności kosztów, co czyni je atrakcyjnym rozwiązaniem dla firm różnej wielkości.
Adopcja chmury hybrydowej, która łączy chmurę prywatną i publiczną, staje się coraz bardziej popularna. Firmy mogą przechowywać wrażliwe dane w chmurze prywatnej, jednocześnie korzystając z elastyczności i oszczędności chmury publicznej do mniej krytycznych operacji. To podejście zwiększa bezpieczeństwo danych i elastyczność operacyjną.
Współprace i Partnerstwa
Współprace między firmami technologicznymi oraz dostawcami usług chmurowych będą kluczowe dla dalszego rozwoju rynku. Partnerstwa takie jak to między NVIDIA i Dell Technologies, które wprowadzają zaawansowane rozwiązania AI dla centrów danych, będą napędzać innowacje i zwiększać konkurencyjność rynku.
Podsumowanie
Rynek rozwiązań sieciowych centrów danych w Polsce ma przed sobą obiecujące perspektywy wzrostu. Polska, dzięki swojemu strategicznemu położeniu, niskim kosztom energetycznym, dostępności wykwalifikowanej siły roboczej oraz korzystnym regulacjom prawnym, ma potencjał, aby stać się europejskim hubem danych. Mimo wyzwań związanych z regulacjami, konkurencją oraz zrównoważonym rozwojem, strategiczne inwestycje w infrastrukturę, innowacje technologiczne oraz rosnące zapotrzebowanie na usługi chmurowe będą napędzać dalszy rozwój rynku.
Dzięki ciągłym inwestycjom w badania i rozwój oraz współpracom strategicznym, Polska może stać się liderem w obszarze centrów danych w Europie, oferując nowoczesne i efektywne rozwiązania dla globalnych klientów.
Bibliografia
- Mordor Intelligence. „Poland Data Center Market Size & Share Analysis – Industry Research Report – Growth Trends”.
- Research and Markets. „Poland Data Center Market – Investment Analysis & Growth Opportunities 2023-2028”.
- Property Forum. „Poland’s data centre market set for dynamic growth”. Przewidywania Rozwoju Rynku Rozwiązań Sieciowych Centrów Danych
w Polsce na 2024 rok: Perspektywy i Wyzwania